Installation & configuration guides#
Overview#
Cortex relies on Elasticsearch to store its data. A basic setup to install Elasticsearch, then Cortex on a standalone and dedicated server (physical or virtual).
Hardware requirements#
Hardware requirements depends on the usage of the system. We recommend starting with dedicated resources:
- 8 vCPU
- 16 GB of RAM
Operating systems#
Cortex has been tested and is supported on the following operating systems:
- Ubuntu 20.04 LTS
- Debian 11
- RHEL 8
- Fedora 35
Installation Guide#
Too much in a hurry to read ?
If you are using one of the supported operating systems, use our all-in-one installation script:
wget -q -O /tmp/install.sh https://archives.strangebee.com/scripts/install.sh ; sudo -v ; bash /tmp/install.sh
This script helps with the installation process on a fresh and supported OS ; the program also run successfully if the conditions in terms of hardware requirements are met.
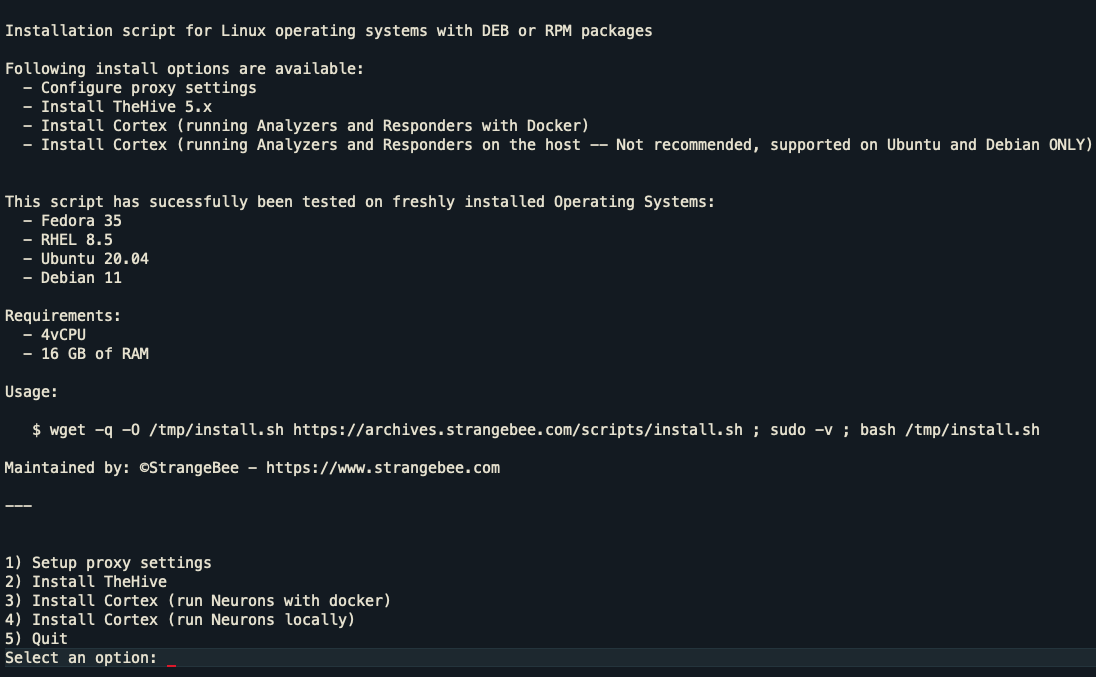
Once executed, several options are available:
- Setup proxy settings ; will configure everything on the host to work with a HTTP proxy, and custom CA certificate.
- Install TheHive ; use this option to install TheHive 5 and its dependancies
- Install Cortex and all its dependencies to run Analyzers & Responders as Docker Iiages
- Install Cortex and all its dependencies to run Analyzers & Responders on the host (Debian and Ubuntu ONLY)
For each release, DEB, RPM and ZIP binary packages are built and provided.
The following Guide let you prepare, install and configure Cortex and its prerequisites for Debian and RPM packages based Operating Systems, as well as for other systems and using our binary packages.
Configuration Guides#
The configuration of Cortex is in files stored in the /etc/cortex folder:
application.confcontains all parameters and optionslogback.xmlis dedicated to log management
/etc/cortex
├── application.conf
├── logback.xml
└── secret.conf
A separate secret.conf file is automatically created by Debian or RPM packages. This file should contain a secret that should be used by one instance.
Various aspects can configured in the application.conf file:
Analyzers & Responders#
Before starting the installation of Cortex, this is important to know how Analyzers and Responders will be managed and run. 2 solutions are available to run them:
Run locally#
The programs are downloaded and installed on the system running Cortex.
There are many disadvantages with this option:
- Some public Analyzers or Responders, or you own custom program might required specific applications installed on the system,
- All of the programs published are written in Python and come with dependancies. To run successfully, the dependancies of all programs should be installed on the same operating system ; so there is a high risk of incompatibilities (some program might require a specific version of a librarie with the latest is also required by another one)
- The goal of Analyzers is to extract or gather information or intelligence about observables ; and some of them might be malicious. Depending on the analysis, like a code analysis, you might want to ensure the Analyzer has not been compromised - and the host - by the observable itself
- You might want to ensure that when you run an Analyzer, there is no question about the integrity of its programs
- Updating them might be a pain regarding Operating System used and dependancies
Run with Docker#
Analyzers & Responders we publish also have their own Docker images.
There are several benefits to use Docker images of Analyzers & Responders.
- No need to worry about applications required or libraries, it just work
- When requested, Cortex downloads the docker image of a program and instanciate a container running the program. When finished, the container is trashed and a new one is created the next time. No need to worry about the integrity of the program
- This is simple to use and maintain
This is the recommended option. It requires installing Docker engine as well.
This is not an exclusive choice, both solutions can be used by the same instance of Cortex.